Abstract
Forecasting temperature by the use of advance statistical tools is very important in understanding and dealing with the effects of rising or decreasing temperatures. This study uses Time series analysis and predictions, a statistical methods to analyze and forecast temperatures, by using the average max, min and mean temperature for each month of different regions in the United Kingdom measured by the Met Office. The increase in concerns about the effects of rising or decreasing temperature on humans, animals, the climate, oceans, and seasonal patterns provokes the need for accurate models for forecasting the temperatures of the different regions across the globe. This report presents the results of forecasting temperatures using trend analysis, seasonality estimation through seasonal averages and seasonal harmonics, the final model were selected using the autoregressive integrated moving average models
library(magrittr)
library(knitr)
library(tseries)
library(forecast)
1. DATA COLLECTION
The data used for this study was gotten from the Met Office website where we sourced for the average max, min and mean temperature for each month for 10 different districts in the UK. This gave us 30 different time series to work with, In order to collect the data from this website without having to download all the individual files or read in the files individually, a function was created, which takes two arguments; the region(district) and the temperature(parameter), For each desired time series data, the function reads in the data, transform it using the time series function and outputs a time series data from 1884 to 2020 at a frequency of 12 observations per year which reperesents each individual monthly average in a year. The time series data was saved in a nested lists for each of the different parameters which made the it easy to work with the massive count of this data.
#We created a function that takes region and district and imports the data from the Metoffice website.
# Create a list of all regions
districts <- c("Northern_Ireland",
"Scotland_N",
"Scotland_E",
"Scotland_W",
"England_E_and_NE",
"England_NW_and_N_Wales",
"Midlands",
"East_Anglia",
"England_SW_and_S_Wales",
"England_SE_and_Central_S"
)
# create a list of all Parameters
features <- c("Tmin", "Tmean", "Tmax")
# indicate template of the url
address <-"https://www.metoffice.gov.uk/pub/data/weather/uk/climate/datasets/"
# Create a function that reads in files from the website
read.ts <- function(district, feature){
c(address, feature, "/date/", district, ".txt") %>%
paste(collapse = "") %>%
read.table(header = TRUE, skip = 5, nrow = 137) %>%
subset(select = 2:13) %>%
t() %>%
as.vector() %>%
ts(frequency = 12, end = c(2020, 12))
}
# Function to apply the read.ts function to a list
feature_select <- function(x) {
lapply(districts, read.ts, feature = x) %>%
set_names(districts)
}
# Implement the feature_select function
all_data <- lapply(features, feature_select) %>% set_names(features)
Tmin <- all_data$Tmin
Tmean <- all_data$Tmean
Tmax <- all_data$Tmax
2. Minimum and Maximum evaluation
Two functions were developed to identify the district and date (year and month) of the highest and the lowest max, min and mean temperature. All our time series data are stored in three groups of temperature parameter, which is a nested list a function was created and we employed the lapply function to apply this function across the respective lists within each group of parameters. The output of the implementation of this function shows that for the average monthly minimum temperature;
- The region with the highest temperature is England_SE_and_Central_S , and the date is Aug , 1997
- The region with the lowest temperature is Scotland_E , and the date is Jan , 1895"
The region with the lowest and highest temperature measurement for the average monthly maximum temperature is;
- The region with the highest temperature is East_Anglia , and the date is Jul , 2006
- The region with the lowest temperature is Midlands , and the date is Feb , 1947
Finally, the region with the lowest and highest temperature measurement for the average monthly mean temperature is;
- The region with the highest temperature is East_Anglia , and the date is Jul , 2006
- The region with the lowest temperature is Scotland_E , and the date is Jan , 1895
# Function to return the maximum value in nested list
max_eval <- function(x) {
names(x)[which.max(unlist(lapply(x, FUN = max)))] -> region
month.abb[(time(x[[region]])[which.max(x[[region]])] %% 1) * 12 + 1] -> month
floor(time(x[[region]])[which.max(x[[region]])]) -> year
paste(
"The region with the highest temperature for",
deparse(substitute(x)),
"is",
region,
",",
"and the date is",
month,
",",
year
)
}
# Function to return the minimum value in nested list
min_eval <- function(x) {
names(x)[which.min(unlist(lapply(x, FUN = min)))] -> region
month.abb[(time(x[[region]])[which.min(x[[region]])] %% 1) * 12 + 1] -> month
floor(time(x[[region]])[which.min(x[[region]])]) -> year
paste(
"The region with the lowest temperature for",
deparse(substitute(x)),
"is",
region,
",",
"and the date is",
month,
",",
year
)
}
# Call min-max evaluating function
max_eval(Tmin)
min_eval(Tmin)
max_eval(Tmax)
min_eval(Tmax)
max_eval(Tmean)
min_eval(Tmean)
3 – Exploratory Data Analysis
We performed some exploratory analysis on the time series data and explores some questions about the time series data as seen below.
Which district is the coldest/warmest?
We will be estimating the coldest and warmest region using the following criteria. We have the time series data for the mean daily maximum air temperature, the mean daily minimum and the mean of air for the regions. We will find the coldest region by finding the region with the highest/lowest temperature across these three groups of time series data measured. We observed that the output using this criteria varies among the three different groups of time seris. This can be seen in the output below.
- The region with the highest average monthly mean temperature is England_SE_and_Central_S , While the region with the lowest temperature is Scotland_N
- The region with the highest average monthly minimum temperature is England_SW_and_S_Wales, While the region with the lowest temperature is Scotland_E
- The region with the highest average monthly maximum temperature is England_SE_and_Central_S, While the region with the lowest temperature is Scotland_N
#creating a function to check average values for any time series parameter given
avg_temp <- function(x) {
lapply(x, mean) -> tmp_val
names(tmp_val)[which.max(unlist(lapply(tmp_val, FUN = max)))] -> warmest
names(tmp_val)[which.min(unlist(lapply(tmp_val, FUN = min)))] -> coldest
result <-
paste(
"The region with the highest temperature average for",
deparse(substitute(x)),
"is",
warmest,
", While the region with the lowest temperature is",
coldest
)
return(result)
}
avg_temp(Tmean)
avg_temp(Tmin)
avg_temp(Tmax)
Which district has the widest temperature range?
We created a function that takes returns the highest range for a list of time series data. This was applied to three groups of time series data and we observed that for average monthly mean temperature and average monthly minimum temperature East_Anglia and England_SE_and_Central_S had the widest range but for the average monthly maximum temperature we observed that East Anglia had the widest range of temperatures.
widest_range <- function(takes_list) {
lapply(takes_list, min) %>% as.data.frame() - lapply(takes_list, max) %>% as.data.frame() -> range_diff
range_diff[which(range_diff %in% apply(range_diff, 1, min))] -> widest_range
return(widest_range)
}
widest_range(Tmean)
widest_range(Tmin)
widest_range(Tmax)
Are winters/summers getting colder/hotter?
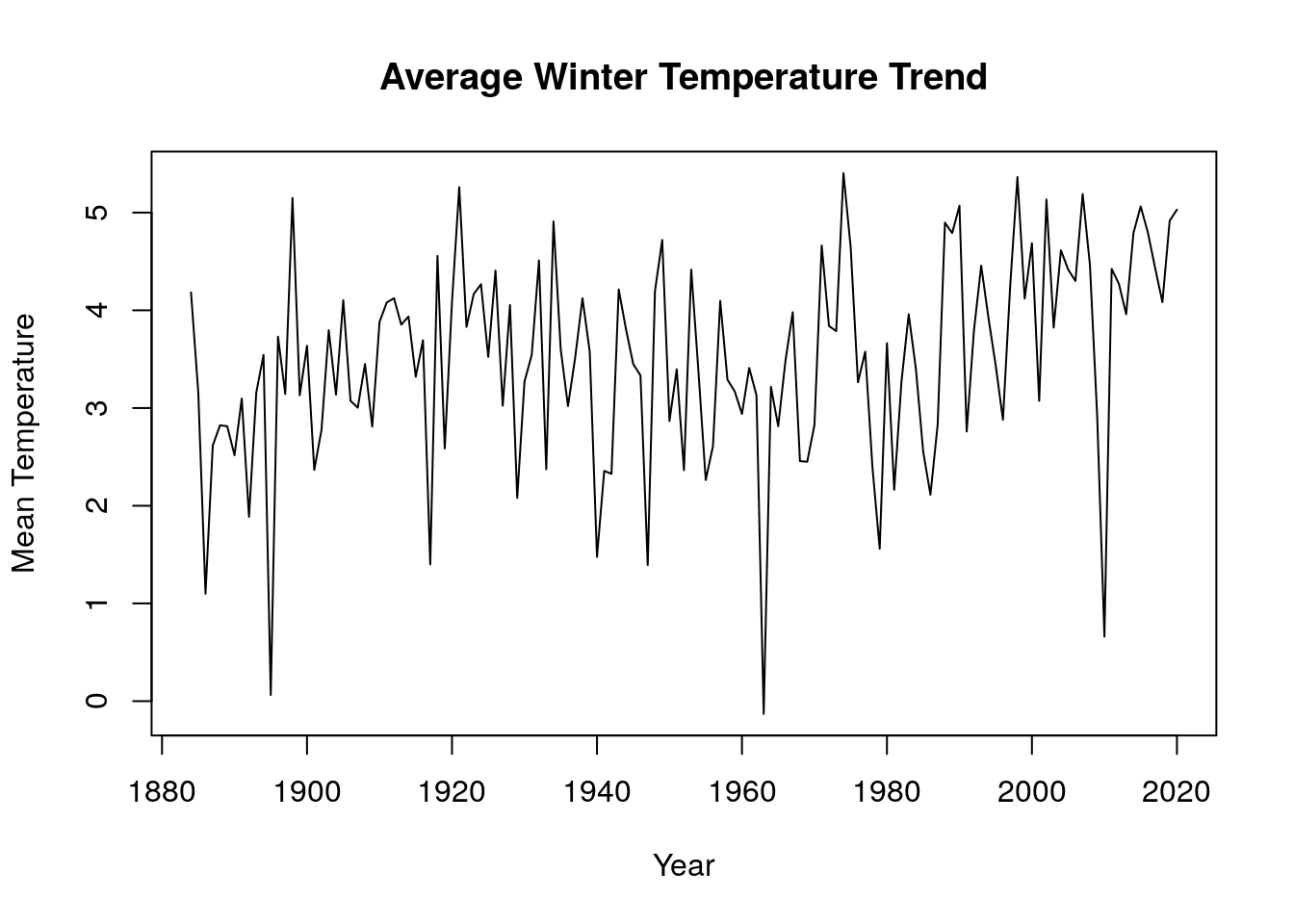
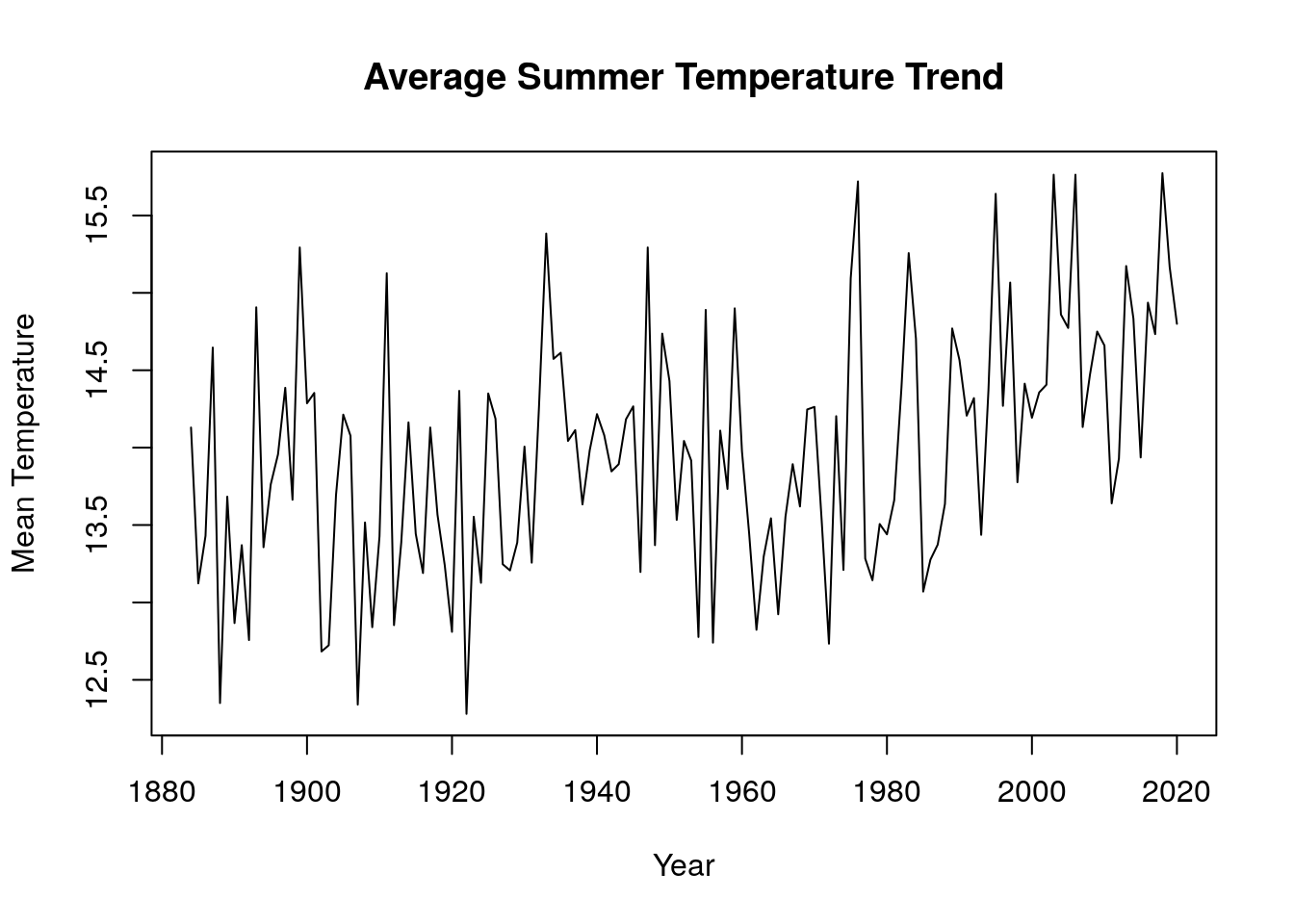
We employed data wrangling techniques to group our time series data into two different seasons (winter and summer). We created a function to convert all time series object to data frame of each season(winter and summer). Each row in the dataframe represents a year and the months for a specific season. This function was applied to the average monthly mean temperature, this gives a summary of the occurence for each months in a particular season. A function was then developed to merge all the seasonal dataframe from each region into a single group for a specific season and this was converted to a time series object using the function ts(). The new time series data was then visualized on a time series plot and we observed that the mean temperature for winter months has an upward trend while that of summer months has a downward trend, this means winters are getting hotter while summers are getting colder.
winter <- c("Dec", "Jan", "Feb", "Year")
summer <- c("Jun", "Jul", "Aug", "Year")
get_season <- function(Tparameter, seas_param) {
#convert to dataframe
dmn <- list(month.abb, unique(floor(time(Tparameter))))
as.data.frame(t(matrix(Tparameter , 12, dimnames = dmn))) -> ts_df
#add year to dataframe
ts_df$Year <- seq(1884, 2020)
#subset data into seasons
season <- seas_param
#add to new variable
ts_df[season] -> season
return(season)
}
lapply(Tmean, get_season,seas_param=summer)->sum_mons
lapply(Tmean, get_season,seas_param=winter)->win_mons
merge_avg_all <- function(season_mons) {
my_merge <- function(df1, df2) {
merge(df1, df2, by = 'Year')
}
#merge all dataframe inside Parameter list to one
Reduce(my_merge, season_mons) -> regions_tmp_seas
#getting yearly average for all regions
regions_tmp_seas$testMean <- rowMeans(regions_tmp_seas[, -1])
#selecting year and average of all regions
regions_mean <- regions_tmp_seas[c('Year', 'testMean')]
#convert back to TS
regions_mean %>% subset(select = 2) %>% t() %>% as.vector() %>% ts(frequency = 1, end = c(2020, 1)) -> final_Temp
return(final_Temp)
}
plot(merge_avg_all(win_mons),main="Average Winter Temperature Trend",xlab="Year",ylab="Mean Temperature")
plot(merge_avg_all(sum_mons),main="Average Summer Temperature Trend",xlab="Year",ylab="Mean Temperature")
4 – Trend and Seasonality Estimation
We created a function to subset the time series data For each district, and considering the 3 time series: max temp, min temp and mean temp, from 1884 until December 2019. This was implemented using the ts() function which takes start of the series, frequency of the series, and end of the series. We created a function that subsets our time series from 1884 - 2019 called “subset_2019” which was then applied to the entire 30 time series data set. The Lapply function is one used to apply a function to every element in a list, since our 3 groups of time series are stored as a nested list the lapply function was used to apply our subset_2019 function on the 3 different groups of our time series data Tmin, Tmax, Tmean to subset the 30 time series data from 1884-2019. We manually created a time vector for our time series “time.all” which will be used extensively in this analysis.
#function to Subset each of the 30 time series until December 2019
subset_2019 <- function(x) {
x %>% head(-12)
}
#subset all groups of time series data to december 2019 using subset_2019 function
lapply(Tmin, subset_2019) -> Tmin_2019
lapply(Tmean, subset_2019) -> Tmean_2019
lapply(Tmax, subset_2019) -> Tmax_2019
# manually create time range
time.all <- seq(
from = start(Tmax_2019$Northern_Ireland)[1],
by = 1 / frequency(Tmax_2019$Northern_Ireland),
length.out = length(Tmax_2019$Northern_Ireland)
)
Compare your results and use appropriate plots and/or tables to confirm your observations.
4.1 Estimating trend
We estimated the trend of each time series using linear, quadratic and cubic regression. A function was developed to apply the 3 different order of polynomial models(linear, quadratic and cubic). The function “run_model” takes a time series data and its time vector and returns its linear, quadratic and cubic models. A function “plot_model” was created which returns a plot of the time series data, linear, quadratic and cubic models all together on a single plot. Finally, We created a function “model_design” which returns the Akaike criterion (AIC) for each model that was passed into its arguments.We are working with data nested into a list and as such we will create a function that can apply the model_design function to a list of time series, this new function was called “apply_model_design”. This function “apply_model_design” will return a list of AIC values for the linear, quadratic and cubic models. We then used the apply_model_design on the three groups of time series data we have. The application of this function gives us the AIC value of each region for the different parameters(TMIN,TMEAN and TMAX).
#Function to return models
run_model <- function(data, time) {
l_model <- lm(data ~ poly(time, degree = 1, raw = TRUE))
q_model <- lm(data ~ poly(time, degree = 2, raw = TRUE))
c_model <- lm(data ~ poly(time, degree = 3, raw = TRUE))
return(list(
l_model = l_model,
q_model = q_model,
c_model = c_model
))
}
#Function to return a plot
plot_model <- function(data, time,main) {
l_var_name <- lm(data ~ poly(time, degree = 1, raw = TRUE))
q_var_name <- lm(data ~ poly(time, degree = 2, raw = TRUE))
c_var_name <- lm(data ~ poly(time, degree = 3, raw = TRUE))
xlab <- "Year"
ylab <- "Temperature"
plot(
data,
main = main,
ylab = ylab,
xlab = xlab,
xlim = c(1880, 2025),
lwd = 1,
type = "l"
)
lines(
time,
fitted(l_var_name),
lwd = 5,
col = 'red',
lty = "dotdash"
)
lines(
time,
fitted(q_var_name),
lwd = 5,
col = 'green',
lty = "dotdash"
)
lines(
time,
fitted(c_var_name),
lwd = 5,
col = 'yellow',
lty = "dotdash"
)
}
#Function to return a list of AIC of different models used for each group of time series
model_design <- function(data, time, var_name, poly_degree) {
var_name <- lm(data ~ poly(time, degree = poly_degree, raw = TRUE))
Var_AIC <- AIC(var_name)
main <- "Average Temperature from 1879"
xlab <- "Year"
ylab <- "Temp"
return(list(Var_AIC = Var_AIC))
}
#Function that applies the model_design function to a list and returns list of list
apply_model_design <- function(my_list) {
lapply(
my_list,
model_design,
var_name = 'linear',
poly_degree = 1,
time = time.all
) -> linear.models
lapply(
my_list,
model_design,
var_name = 'quadratic',
poly_degree = 2,
time = time.all
) -> quadratic.models
lapply(
my_list,
model_design,
var_name = 'cubic',
poly_degree = 3,
time = time.all
) -> cubic.models
all_list <-
list(
linear.models = linear.models,
quadratic.models = quadratic.models,
cubic.models = cubic.models
)
return(all_list)
}
#apply the apply_model_design function on different groups of Time series
apply_model_design(Tmin_2019)-> Tmin_models
apply_model_design(Tmax_2019)-> Tmax_models
apply_model_design(Tmean_2019)-> Tmean_models
Select a trend model for each time series using an appropriate criteria. Are the models selected all the same? If not is there a pattern depending on the region and/or the group (max, min and mean)?
4.2 Trend Selection
We created a function “which_model” which helps select the best model for a time series, we have the linear, quadratic and cubic AIC values for each region, we will use this function to find the model with the least Akaike criterion(AIC) values which signifies the best model for the time series data. The which_model() function when applied to a list of different time series data returns a dataframe which has a column “Best.Model” which shows the row-wise minimum for each region since each row represents a region and its linear, quadratic and cubic models for a specific parameter. It was observed that all the regions had their best model as the linear model except for two regions(England_E_and_NE and East_Anglia) in the average monthly maximum temperature (Tmax) parameter. The table for best models for each region for a specific parameter can be found below.
# Function to return the best model
which_model <- function(Model_parameter) {
Model_parameter$linear.models %>% as.data.frame() -> l
names(l) <- c(names(Model_parameter$linear.models))
Model_parameter$quadratic.models %>% as.data.frame() -> q
names(q) <- c(names(Model_parameter$quadratic.models))
Model_parameter$cubic.models %>% as.data.frame() -> c
names(c) <- c(names(Model_parameter$cubic.models))
ModelAIC <- c("Linear", "Quadratic", "Cubic")
cbind(ModelAIC, rbind(l, q, c)) -> tminbind
tminbind %>% as.vector() %>% t() %>% as.data.frame() -> new
names(new) <- as.matrix(new[1,])
new <- new[-1,]
new[] <- lapply(new, function(x)
type.convert(as.character(x)))
new$Best.Model <- colnames(new)[apply(new, 1, FUN = which.min)]
return(new)
}
Best Model by region for Average monthly minimum temperature
which_model(Tmin_models)
Best Model by region for Average monthly mean temperature
which_model(Tmean_models)
Best Model by region for Average monthly maximum temperature
which_model(Tmax_models)
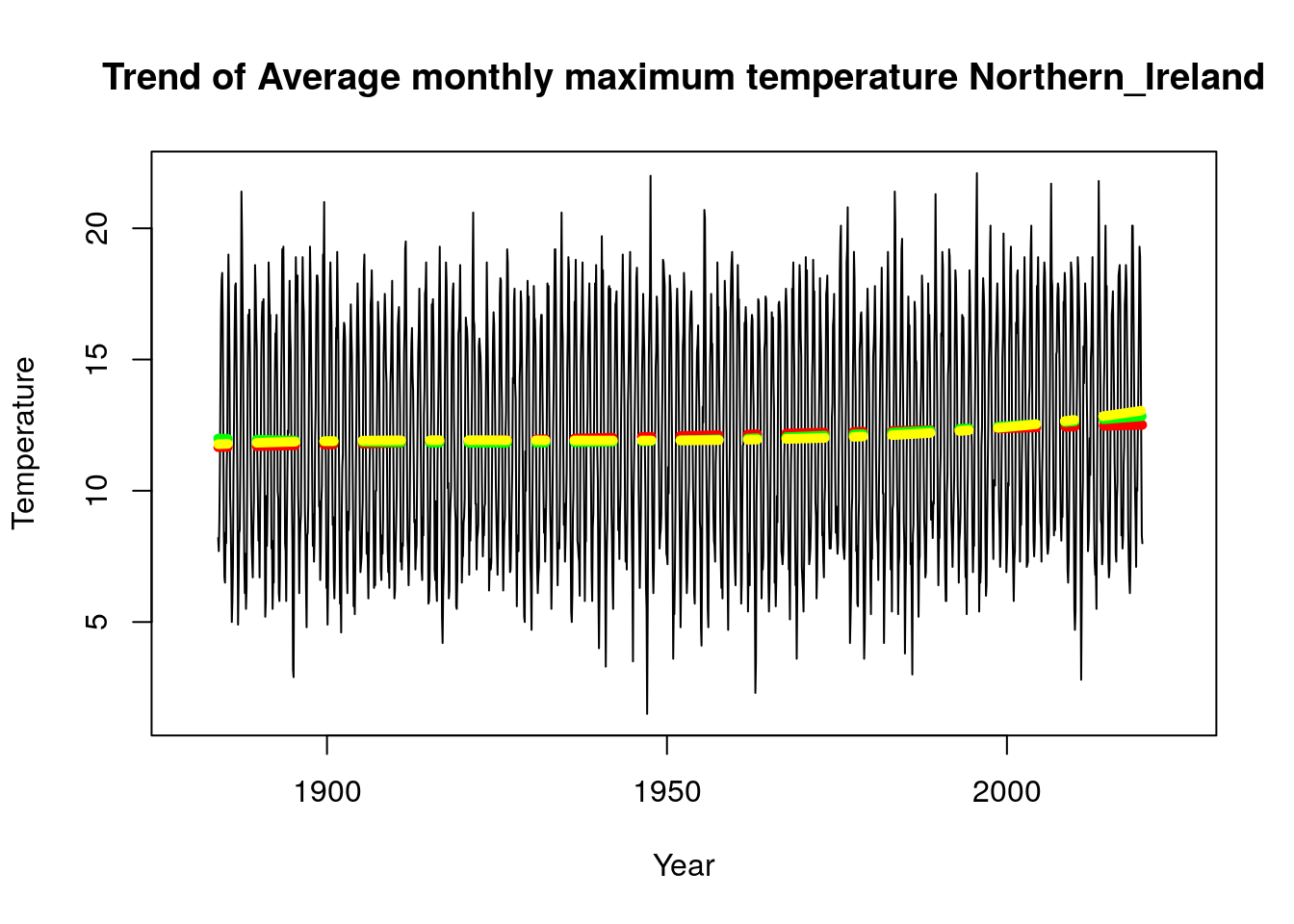
As stated above we observed that all our model choice for all regions are uniform except England_E_and_NE and East_Anglia for the Tmax parameter, it would be interesting to see a plot of the linear model vs plot of the cubic model. We used the function “plot_model” created above to implement these plots and we observe that there is a difference in the plots for the different regions, while Northern Ireland has a more stable trend, we can see that England_E_and_NE and East_Anglia do have some cubic trend.
plot_model(Tmax_2019$England_E_and_NE,time.all,"Trend of Average monthly maximum temperature England_E_and_NE")
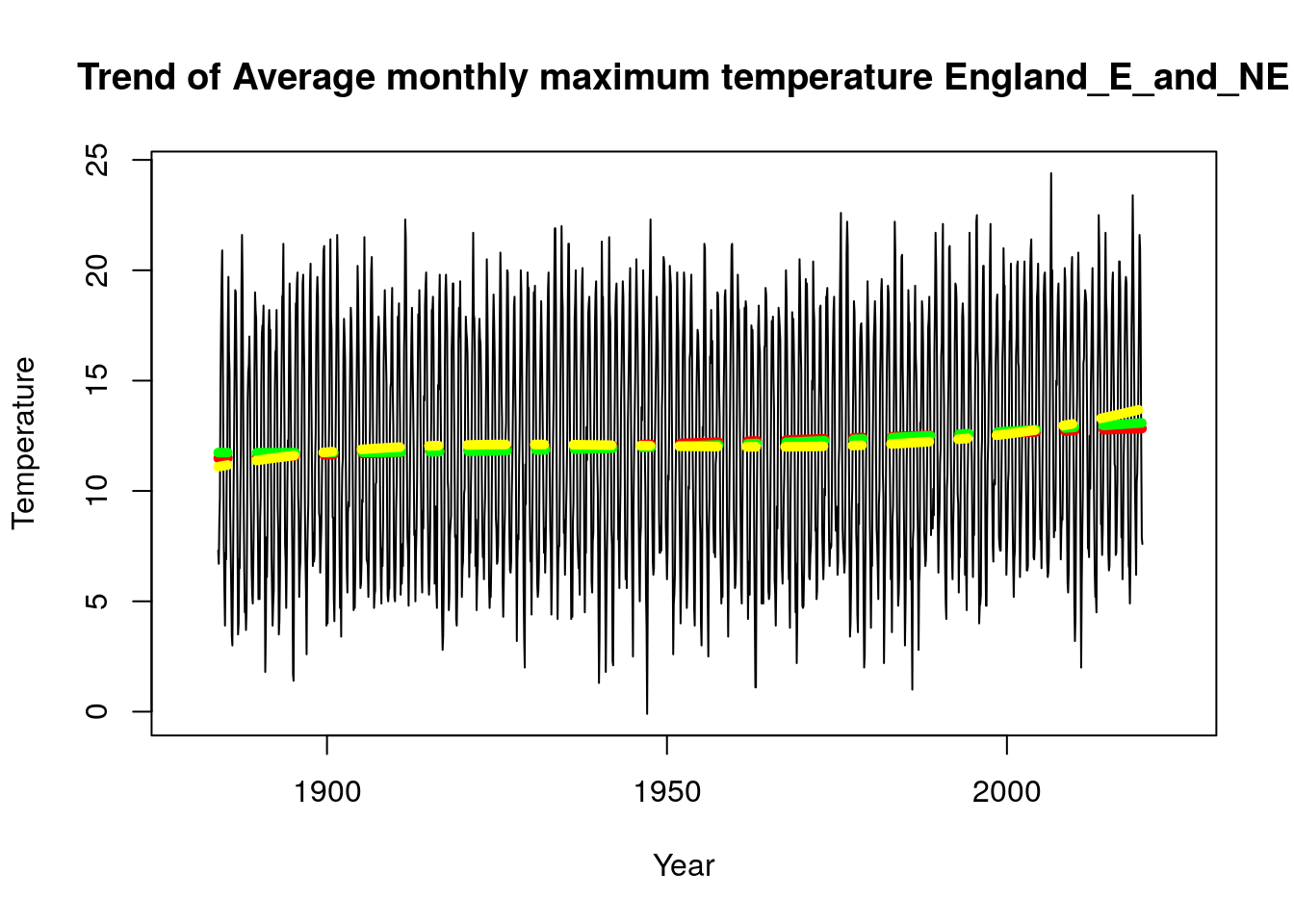
plot_model(Tmax_2019$East_Anglia,time.all,"Trend of Average monthly maximum temperature East_Anglia")
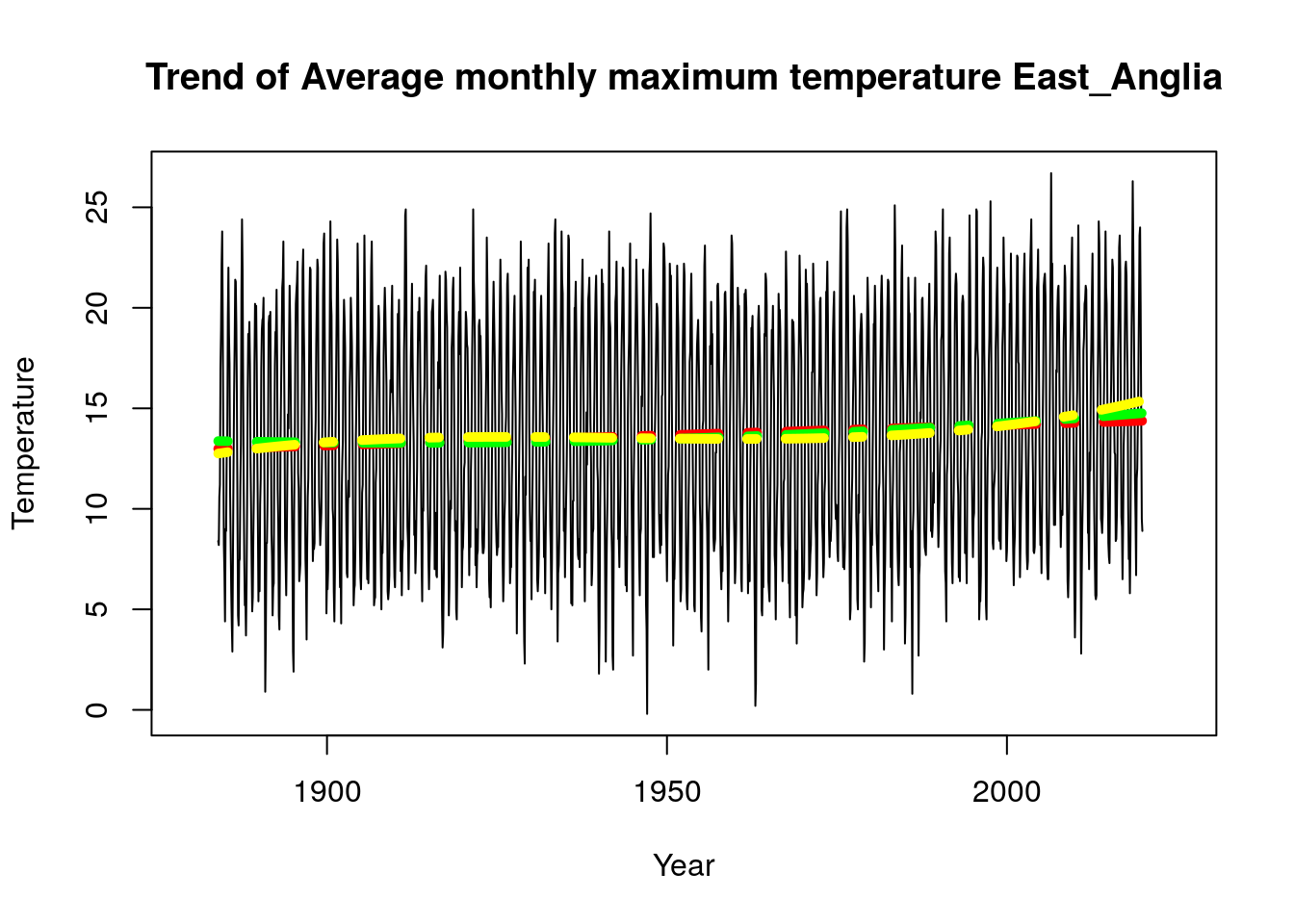
plot_model(Tmax_2019$Northern_Ireland,time.all,"Trend of Average monthly maximum temperature Northern_Ireland")
4.3 Estimating seasonality using seasonal means and harmonic models
4.3.1 removing Trend using averaging
We will create a function that removes the trend component and returns its monthly average. The function takes two arguments which are the time series data and the polynomial model that bests fit it according to the Akaike Criterion. All models except England_E_and_NE and East_Anglia for the Tmax parameter have a linear model as their best model. We will split the Tmax time series data into two groups the linear and the cubic groups, this would make it easier to apply functions which are specific to the best model for each region. We will then use the return_month_avg to return the seasonal means of each of the different regions based on their best trend model.
return_month_avg <- function(takes_data, model_type) {
run_model(takes_data, time.all) -> model.result
data.notrend <- takes_data - fitted(model.result[[model_type]])
tapply(data.notrend, cycle(takes_data), mean) %>% as.data.frame() -> fin_month_avg
colnames(fin_month_avg) <- c('Season_Mean')
mymonths <- c("Jan",
"Feb",
"Mar",
"Apr",
"May",
"Jun",
"Jul",
"Aug",
"Sep",
"Oct",
"Nov",
"Dec")
#add abbreviated month name
fin_month_avg$Month <- mymonths
return(fin_month_avg)
}
# Subsetting cubic and linear model for TMAX
Tmax_2019[-c(5,8)] -> Tmax_2019_ln
Tmax_2019[c(5,8)]-> Tmax_2019_cubic
#----Estimate seasonal average for All linear model
lapply(Tmin_2019, return_month_avg, model_type = "l_model") %>% set_names(names(Tmin_2019)) -> Tmin_monthly_avg
lapply(Tmean_2019, return_month_avg, model_type = "l_model") %>% set_names(names(Tmin_2019)) -> Tmean_monthly_avg
lapply(Tmax_2019_ln, return_month_avg, model_type = "l_model") %>% set_names(names(Tmax_2019_ln)) -> Tmax_monthly_avg_ln
#----Estimate seasonal average for All cubic model
lapply(Tmax_2019_cubic, return_month_avg, model_type = "c_model") %>% set_names(names(Tmax_2019_cubic)) -> Tmean_monthly_avg_cubic
Sample monthly average for Northern Ireland
Tmin_monthly_avg$Northern_Ireland
4.3.2 Estimate seasonality with seasonal average
The seasonality was estimated using the seasonal means method. We created a function return_seas_avg which takes the time series data and model type. The function models the inputs and returns the seasonal means for each of the time series provided to it. We used lapply to apply the return_seas_avg to the list of time series for the different parameters Tmin, Tmax, Tmean.
return_seas_avg <- function(data, model_type) {
#one region since all months are the same
months <- as.factor(cycle(Tmin_2019$Northern_Ireland))
# Apply the run_model function to the data to get the specified model
run_model(data, time.all) -> model.result
# Get the residuals from the data which does not have the trend
data.notrend <- data - fitted(model.result[[model_type]])
seas.means <- lm(data.notrend ~ months - 1)
return(seas.means)
}
lapply(Tmin_2019, return_seas_avg, model_type = "l_model") %>% set_names(names(Tmin_2019)) -> Tmin_seas_est
lapply(Tmean_2019, return_seas_avg, model_type = "l_model") %>% set_names(names(Tmin_2019)) -> Tmean_seas_est
lapply(Tmax_2019_ln, return_seas_avg, model_type = "l_model") %>% set_names(names(Tmax_2019_ln)) -> Tmax_seas_est_ln
#All cubic model
lapply(Tmax_2019_cubic, return_seas_avg, model_type = "c_model") %>% set_names(names(Tmax_2019_cubic)) -> Tmax_seas_est_cubic
#joined max
do.call(c, list(Tmax_seas_est_ln, Tmax_seas_est_cubic)) -> Tmax_ln_nd_cub_seas
# seasonal means validation check
length(names(Tmin_seas_est))
length(names(Tmean_seas_est))
length(names(Tmax_ln_nd_cub_seas))
4.3.2 Estimating seasonality using harmonic mean
We created a function to give the harmonic mean of a time series data. We performed a trend check on the time series and remove the specified trend type(l_model,c_model and q_model). The residuals were derived by subtracting the data from the fitted data. In our dataset since all our best models are linear except for England_E_and_NE and East_Anglia for the average monthly maximum temperature, this means all our models will be linear except these two which will be cubic. In this step we applied the return_harmonic function to all our time series data, a check will be done for models that are significant at a p-value of 0.05.
# Function to return the harmonic mean of a time series data
return_harmonic <- function(takes_data, trend_type) {
# Apply the run_model function to the data to get the specified model
run_model(takes_data, time.all) -> model.result
# Get the residuals from the data which does not have the trend
data.notrend <- takes_data - fitted(model.result[[trend_type]])
# Create a matrix of SINE and COSINE values
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
# Function to return harmonic of specified order
seasonal.har <- function(order) {
assign(paste(c("seasonal.har", order), collapse = ""),
lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, 1:order], COS = COS[, 1:order])))
return(get(paste(c(
"seasonal.har", order
), collapse = "")))
}
# order 1
seas.har1 <- seasonal.har(1)
# order 2
seas.har2 <- seasonal.har(2)
# order 3
seas.har3 <- seasonal.har(3) # SIN.3 not significant
# order 4
seas.har4 <- seasonal.har(4) # SIN.3 COS.4 not significant
# order 5
seas.har5 <-
seasonal.har(5) # SIN.3 SIN5 COS.4 COS.5 not significant
# order 6
seas.har6 <-
seasonal.har(6) # SIN.3 SIN5 SIN.6 COS.4 COS.5 COS.6 not significant
return(
list(
seas.har1 = seas.har1,
seas.har2 = seas.har2,
seas.har3 = seas.har3,
seas.har4 = seas.har4,
seas.har5 = seas.har5,
seas.har6 = seas.har6
)
)
}
# Apply the return_harmonic function to all time series
lapply(Tmin_2019, return_harmonic, trend_type = "l_model") %>% set_names(names(Tmin_2019)) -> Tmin_harmonic
lapply(Tmean_2019, return_harmonic, trend_type = "l_model") %>% set_names(names(Tmean_2019)) -> Tmean_harmonic
lapply(Tmax_2019_ln, return_harmonic, trend_type = "l_model") %>% set_names(names(Tmax_2019_ln)) -> Tmax_harmonic_ln
#remove the cubic trend from England_E_and_NE and East_Anglia for the Tmax parameter
lapply(Tmax_2019_cubic, return_harmonic, trend_type = "c_model") %>% set_names(names(Tmax_2019_cubic)) -> Tmax_harmonic_cubic
significant models
We created a function to return the significant models for a specific region and harmonic. We need models with a p-value lower than that of the null hypothesis. We create region_harmonics() function to take a list and apply all the function singular_harmonic using lapply() to all the elements in the list provided in the argument. We developed a function grouped_harmonica() that applies the region_harmonics function to a nested list. This would return only the models that has passed the null hypothesis test, hence containing only significant models.
The Null hypothesis and alternative hypothesis are as follows:
- Null hypothesis: The model is not significant
- Alternative hypothesis: The model is significant
# p-value lesser than 0.05 shows significant that null is false
singular_harmonic <- function(x) {
summary(x) -> temp
temp$coefficients %>% as.data.frame() -> temp2
temp2 <- temp2[temp2$`Pr(>|t|)` < 0.05,]
temp2$Harmonic.Model <- row.names(temp2)
#return(temp2)
}
region_harmonics <- function(takes_list) {
lapply(takes_list, singular_harmonic) %>% set_names(names(takes_list)) -> significant_mods
return(significant_mods)
}
grouped_harmonica <- function(x) {
lapply(x, region_harmonics) %>% set_names(names(x)) -> Tmin_best_harmonics
return(Tmin_best_harmonics)
}
grouped_harmonica(Tmin_harmonic) -> Tmin_indexed_harmonics
grouped_harmonica(Tmean_harmonic) -> Tmean_indexed_harmonics
grouped_harmonica(Tmax_harmonic_ln) -> Tmax.ln_indexed_harmonics
grouped_harmonica(Tmax_harmonic_cubic) -> Tmax.cub_indexed_harmonics
Unique models across all time series
We created a function that checks the unique models for each element in a list. This unique model would be used to then recreate the harmonic models. We retrieved the best harmonic for each region i.e all harmonics with P-value lesser than the null hypothesis p-value of 0.05. We applied the unique function to all our best model to retrieve only unique models. We observed 5 different unique configurations for our models, this would be used to create 5 different functions, each function will be specific to the unique model configurations found in the implementation below.
best_harm <- function(takes_list) {
lapply(takes_list, unique) %>% set_names(names(takes_list)) -> significant_harmonics
return(significant_harmonics)
}
Tmin_best_harmonics <- best_harm(Tmin_indexed_harmonics)
Tmean_best_harmonics <- best_harm(Tmean_indexed_harmonics)
Tmax.ln_best_harmonics <- best_harm(Tmax.ln_indexed_harmonics)
Tmax.cub_best_harmonics <- best_harm(Tmax.cub_indexed_harmonics)
#unique(Tmin_best_harmonics)
best_model_list <-
c(
Tmin_best_harmonics,
Tmean_best_harmonics,
Tmax.ln_best_harmonics,
Tmax.cub_best_harmonics
)
lapply(best_model_list, unique) %>% set_names(names(best_model_list)) -> all_unique_best
length(unique(all_unique_best) )
# View unique model config
unique(all_unique_best)
create functions to map models
Five different functions were developed inline with the 5 different significant harmonic models we had during the null hypothesis test. The functions are:
- rerun_harmonic1 - [“SIN” “COS” ] and [“SIN.1” “SIN.2” “COS.1” “COS.2”]
- rerun_harmonic2 - [“SIN” “COS”], [“SIN.1” “SIN.2” “COS.1” “COS.2”] and [“SIN.1” “SIN.2” “COS.1” “COS.2” “COS.4”]
- rerun_harmonic3 - [“SIN” “COS”], [“SIN.1” “SIN.2” “COS.1” “COS.2”] and [“SIN.1” “SIN.2” “SIN.5” “COS.1” “COS.2”]
- rerun_harmonic4 - [“SIN” “COS”], [“SIN.1” “SIN.2” “COS.1” “COS.2”] and [“SIN.1” “SIN.2” “COS.1” “COS.2” “COS.3”]
- rerun_harmonic5 - [“SIN” “COS”], [“SIN.1” “SIN.2” “COS.1” “COS.2”], [“SIN.1” “SIN.2” “COS.1” “COS.2” “COS.3”] and [“SIN.1” “SIN.2” “SIN.4” “COS.1” “COS.2” “COS.3”]
We observe that all significant models include the first and second harmonics with little variations among the other models. The functions takes the time series data and the best trend model for it l_model, q_model or c_model and returns the harmonic with the lowest Akaike criterion among all the harmonic models implemented within the specific function. Implementing this function gives us the best harmonic model for each of the 30 time series data we are working with.
# Function "SIN.1" "SIN.2" "COS.1" "COS.2" and "SIN" "COS"
rerun_harmonic1 <- function(takes_data, trend_type) {
# Apply the run_model function to the data to get the specified model
run_model(takes_data, time.all) -> model.result
# Get the residuals from the data which does not have the trend
data.notrend <- takes_data - fitted(model.result[[trend_type]])
# Create a matrix of SINE and COSINE values
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
seas.har1 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, 1:1], COS = COS[, 1:1]))
seas.har2 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, c(1, 2)], COS = COS[, c(1, 2)]))
list(seas.har1 = seas.har1, seas.har2 = seas.har2) -> myl
lapply(myl, AIC) -> mlk
names(mlk)[which.min(unlist(lapply(mlk, FUN = min)))] -> res
return(mlk)
}
rerun_harmonic2 <- function(takes_data, trend_type) {
# Apply the run_model function to the data to get the specified model
run_model(takes_data, time.all) -> model.result
# Get the residuals from the data which does not have the trend
data.notrend <- takes_data - fitted(model.result[[trend_type]])
# Create a matrix of SINE and COSINE values
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
seas.har1 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, 1:1], COS = COS[, 1:1]))
seas.har2 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, c(1, 2)], COS = COS[, c(1, 2)]))
seas.har3_B <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, c(1, 2)], COS = COS[, c(1, 2, 4)]))
list(seas.har1 = seas.har1,
seas.har2 = seas.har2,
seas.har3_B = seas.har3_B) -> myl
lapply(myl, AIC) -> mlk
names(mlk)[which.min(unlist(lapply(mlk, FUN = min)))] -> res
return(mlk)
}
rerun_harmonic3 <- function(takes_data, trend_type) {
# Apply the run_model function to the data to get the specified model
run_model(takes_data, time.all) -> model.result
# Get the residuals from the data which does not have the trend
data.notrend <- takes_data - fitted(model.result[[trend_type]])
# Create a matrix of SINE and COSINE values
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
seas.har1 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, 1:1], COS = COS[, 1:1]))
seas.har2 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, c(1, 2)], COS = COS[, c(1, 2)]))
seas.har3_C <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, c(1, 2, 5)], COS = COS[, c(1, 2)]))
list(seas.har1 = seas.har1,
seas.har2 = seas.har2,
seas.har3_C = seas.har3_C) -> myl
lapply(myl, AIC) -> mlk
names(mlk)[which.min(unlist(lapply(mlk, FUN = min)))] -> res
return(mlk)
}
rerun_harmonic4 <- function(takes_data, trend_type) {
# Apply the run_model function to the data to get the specified model
run_model(takes_data, time.all) -> model.result
# Get the residuals from the data which does not have the trend
data.notrend <- takes_data - fitted(model.result[[trend_type]])
# Create a matrix of SINE and COSINE values
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
seas.har1 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, 1:1], COS = COS[, 1:1]))
seas.har2 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, c(1, 2)], COS = COS[, c(1, 2)]))
seas.har3_A <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, c(1, 2)], COS = COS[, c(1, 2, 3)]))
list(seas.har1 = seas.har1,
seas.har2 = seas.har2,
seas.har3_A = seas.har3_A) -> myl
lapply(myl, AIC) -> mlk
names(mlk)[which.min(unlist(lapply(mlk, FUN = min)))] -> res
return(mlk)
}
rerun_harmonic5 <- function(takes_data, trend_type) {
# Apply the run_model function to the data to get the specified model
run_model(takes_data, time.all) -> model.result
# Get the residuals from the data which does not have the trend
data.notrend <- takes_data - fitted(model.result[[trend_type]])
# Create a matrix of SINE and COSINE values
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
seas.har1 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, 1:1], COS = COS[, 1:1]))
seas.har2 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, c(1, 2)], COS = COS[, c(1, 2)]))
seas.har3 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, c(1, 2)], COS = COS[, c(1, 2, 3)]))
seas.har4 <- lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, c(1, 2, 4)], COS = COS[, c(1, 2, 3)]))
list(
seas.har1 = seas.har1,
seas.har2 = seas.har2,
seas.har3 = seas.har3,
seas.har4 = seas.har4
) -> myl
lapply(myl, AIC) -> mlk
which.min(unlist(lapply(mlk, FUN = min))) -> res
return(mlk)
}
Subset all the time series into groups of significant harmonic model
We have 5 different configurations of significant harmonnic models, we will group each of our time series parameter (Tmin,Tmean and Tmax) to the significant harmonic model group they belong to among these 5 configurations after which their respective function is then applied on each subset. Based on initial analysis we observed that for our average monthly maximum temperature we have two regions with a cubic trend model as their best trend model, we will create a different subset for this group to make the implementation of these functions on the time series data seamless.
#Subset Tmin_best_harmonics into significant harmonic groups
Tmin_best_dual <-
Tmin_2019[-c(3, 9)] #function rerun_harmonic1 would work for this
lapply(Tmin_best_dual, rerun_harmonic1, trend_type = "l_model") %>% set_names(names(Tmin_best_dual)) -> significant_Tmin_dual
############################################################################################
Tmin_best_trio1 <-
Tmin_2019[c(3)] # function rerun_harmonic2 would work for this
lapply(Tmin_best_trio1, rerun_harmonic2, trend_type = "l_model") %>% set_names(names(Tmin_best_trio1)) -> significant_Tmin_trio1
############################################################################################
Tmin_best_trio2 <-
Tmin_2019[c(9)] # rerun_harmonic3 would work on this
lapply(Tmin_best_trio2, rerun_harmonic3, trend_type = "l_model") %>% set_names(names(Tmin_best_trio2)) -> significant_Tmin_trio2
############################################################################################
# Subset Tmean_best_harmonics into significant harmonic groups
Tmean_best_dual <-
Tmean_2019[-c(4, 10)] #rerun_harmonic1 will work for this
lapply(Tmean_best_dual, rerun_harmonic1, trend_type = "l_model") %>% set_names(names(Tmean_best_dual)) -> significant_Tmean_dual
############################################################################################
Tmean_best_trio1 <-
Tmean_2019[c(4)] # rerun_harmonic4 will work for this
lapply(Tmean_best_trio1, rerun_harmonic4, trend_type = "l_model") %>% set_names(names(Tmean_best_trio1)) -> significant_Tmean_trio1
############################################################################################
Tmean_best_trio2 <-
Tmean_2019[c(10)] #rerun_harmonic3 this function works for this
lapply(Tmean_best_trio2, rerun_harmonic1, trend_type = "l_model") %>% set_names(names(Tmean_best_trio2)) -> significant_Tmean_trio2
############################################################################################
#Subset Tmax.ln_best_harmonics into significant harmonic groups
Tmax.ln_best_dual <-
Tmax_2019_ln[c(6, 8)] #rerun_harmonic1 will work for this
lapply(Tmax.ln_best_dual, rerun_harmonic1, trend_type = "l_model") %>% set_names(names(Tmax.ln_best_dual)) -> significant_Tmax.ln_dual
############################################################################################
Tmax.ln_best_trio1 <-
Tmax_2019_ln[-c(6, 7, 8)] # rerun_harmonic4 this will work for this
lapply(Tmax.ln_best_trio1, rerun_harmonic4, trend_type = "l_model") %>% set_names(names(Tmax.ln_best_trio1)) -> significant_Tmax.ln_trio1
############################################################################################
Tmax.ln_best_trio2 <-
Tmax_2019_ln[c(7)] # rerun_harmonic5 should work for this
lapply(Tmax.ln_best_trio2, rerun_harmonic5, trend_type = "l_model") %>% set_names(names(Tmax.ln_best_trio2)) -> significant_Tmax.ln_trio2
############################################################################################
#Subset Tmax.cub_best_harmonics harmonic into significant harmonic groups
#Tmax.cub_best_harmonics[c(1,2)]
Tmax.cubic_best_dual <-
Tmax_2019_cubic[c(1, 2)] #rerun_harmonic1 this functipn will work for this
lapply(Tmax.cubic_best_dual, rerun_harmonic1, trend_type = "c_model") %>% set_names(names(Tmax.cubic_best_dual)) -> significant_Tmax.cub_trio2
############################################################################################
4.4 Seasonal model selection Seasonal average or harmonic models?
• Select a seasonal model for each time series using an appropriate criteria. Are the models selected all the same? If not is there a pattern depending on the region and/or the group (max, min and mean)? We now have the different significant harmonic models and the seasonal means of all our time series, we will use the Akaike Criterion to determine the best model for each time series data, as stated above the model with the least AIC will be the best model for the specific time series data.
create a function that selects best model for all different parameters
We created a function get_min_AIC that takes 3 arguments the district/region, the best harmonic model, and the seasonal average and returns the model with the lowest Akaike criterion. In this function we combine the AIC of the seasonal average model of the time series and the AIC of the harmonic model and then return the model with the lowest AIC.
get_min_AIC <- function(x, y, z) {
AIC(z[[x]]) -> seas.avg
y [[x]] -> temp1
temp1 <- c(temp1, seas.avg = seas.avg)
names(temp1)[which.min(unlist(lapply(temp1, FUN = min)))] -> res
return(res)
}
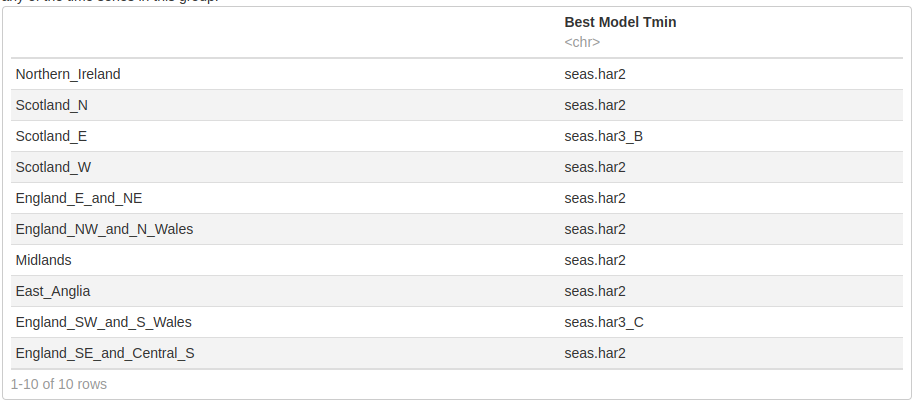
All TMIN
We used the do.call function to re-combine our different configurations for TMIN parameter into one list for each parameter. The get_min_AIC method was then applied on each time series to return the model with the lowest AIC and we observe that seasonal average was not the best for any of the time series in this group.
do.call(c,
list(
significant_Tmin_dual,
significant_Tmin_trio1,
significant_Tmin_trio2
)) -> Tmin_harm_final
lapply(districts, get_min_AIC, y = Tmin_harm_final, z = Tmin_seas_est) %>% set_names(districts) -> best_model_TMIN
best_model_TMIN %>% as.data.frame() %>% t() %>% as.data.frame() ->Tmin.best
names(Tmin.best)[1] <- "Best Model Tmin"
Tmin.best
ALl TMEAN
We used the do.call function to re-combine our different configurations for TMEAN parameter into one list for each parameter. The get_min_AIC method was then applied on each time series to return the model with the lowest AIC and we observe that seasonal average was not the best for any of the time series in this group.
do.call(c,
list(
significant_Tmean_dual,
significant_Tmean_trio1,
significant_Tmean_trio2
)) -> Tmean_harm_final
lapply(districts, get_min_AIC, y = Tmean_harm_final, z = Tmean_seas_est) %>% set_names(districts) -> best_model_TMean
best_model_TMean %>% as.data.frame() %>% t() %>% as.data.frame() -> Tmean.best
names(Tmean.best)[1] <- "Best Models Tmean"
Tmean.best
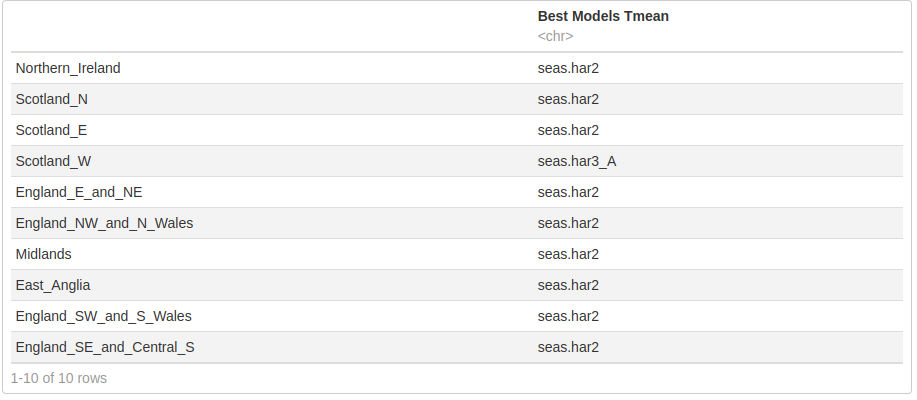
ALL Tmax
We combined the time series with a linear trend into a single list and applied the get_min_AIC and the same was done for time series with a cubic trend.
do.call(
c,
list(
significant_Tmax.ln_dual,
significant_Tmax.ln_trio1,
significant_Tmax.ln_trio2
)
) -> Tmax_harm_final_ln
significant_Tmax.cub_trio2 -> Tmax_harm_final_cubic
linear_districts <- names(Tmax_2019)[-c(5, 8)]
lapply(linear_districts, get_min_AIC, y = Tmax_harm_final_ln, z = Tmax_seas_est_ln) %>% set_names(linear_districts) -> best_model_TMax_ln
best_model_TMax_ln %>% as.data.frame() %>% t() %>% as.data.frame() -> Tmax.ln.best
names(Tmax.ln.best)[1] <- "Best Models Tmax"
cubic_district <- names(Tmax_2019)[c(5, 8)]
lapply(cubic_district, get_min_AIC, y = Tmax_harm_final_cubic, z = Tmax_seas_est_cubic) %>% set_names(cubic_district) -> best_model_TMax_cubic
best_model_TMax_cubic %>% as.data.frame() %>% t() %>% as.data.frame() -> Tmax.cb.best
names(Tmax.cb.best)[1] <- "Best Models Tmax"
rbind.data.frame(Tmax.ln.best,Tmax.cb.best)
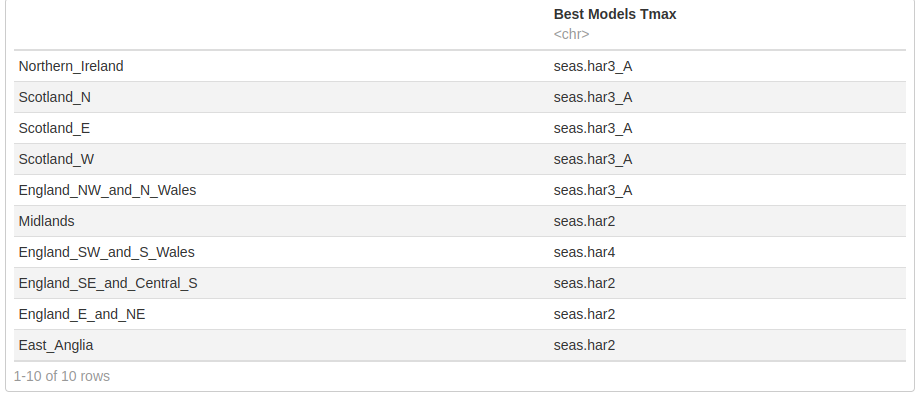
We used the unique function to check the unique best models for each group of our time series and we can see we have 5 different best models distributed among the different time series data. Similar to the approach used above, we will create 5 functions that models our combined trend model and seasonal models for each time series data. Unique Models
list(
unique(best_model_TMIN),
unique(best_model_TMean),
unique(best_model_TMax_ln),
unique(best_model_TMax_cubic)
) %>% unlist() %>% unique()
list(
unique(best_model_TMIN),
unique(best_model_TMean),
unique(best_model_TMax_ln),
unique(best_model_TMax_cubic)
) %>% unlist() %>% unique() %>% length()
4.5 Building combined model for trend and seasonality
We have 5 different best model distributed among the different groups of time series, we will create 5 functions to implement the combine models based on the groups each time series data belongs to, we will subset the time series into their respective groups and apply these functions across the respective groups. Finally, We combined all the different models for the time series into a variable called “final”.
# function for model with Seasonal harmonic 2 as the best model
combined_mod_har2 <- function(data, poly_order) {
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
seas.har2 <- lm(data ~ .,
data = data.frame(
TIME = poly(time.all, poly_order, raw = TRUE),
SIN = SIN[, c(1, 2)],
COS = COS[, c(1, 2)]
))
#print(summary(get(paste(c("seasonal.har",order), collapse = ""))))
return(seas.har2)
}
# function for model with Seasonal harmonic 3 A as the best model
combined_mod_har3_A <- function(data, poly_order) {
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
seas.har3_A <- lm(data ~ .,
data = data.frame(
TIME = poly(time.all, poly_order, raw = TRUE),
SIN = SIN[, c(1, 2)],
COS = COS[, c(1, 2, 3)]
))
#print(summary(get(paste(c("seasonal.har",order), collapse = ""))))
return(seas.har3_A)
}
# function for model with Seasonal harmonic 3 B as the best model
combined_mod_har3_B <- function(data, poly_order) {
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
seas.har3_B <- lm(data ~ .,
data = data.frame(
TIME = poly(time.all, poly_order, raw = TRUE),
SIN = SIN[, c(1, 2)],
COS = COS[, c(1, 2, 4)]
))
#print(summary(get(paste(c("seasonal.har",order), collapse = ""))))
return(seas.har3_B)
}
# function for model with Seasonal harmonic 3 C as the best model
combined_mod_har3_C <- function(data, poly_order) {
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
seas.har3_C <- lm(data ~ .,
data = data.frame(
TIME = poly(time.all, poly_order, raw = TRUE),
SIN = SIN[, c(1, 2, 5)],
COS = COS[, c(1, 2)]
))
#print(summary(get(paste(c("seasonal.har",order), collapse = ""))))
return(seas.har3_C)
}
# function for model with Seasonal harmonic 4 as the best model
combined_mod_har4 <- function(data, poly_order) {
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
seas.har4 <- lm(data ~ .,
data = data.frame(
TIME = poly(time.all, poly_order, raw = TRUE),
SIN = SIN[, c(1, 2, 4)],
COS = COS[, c(1, 2, 3)]
))
#print(summary(get(paste(c("seasonal.har",order), collapse = ""))))
return(seas.har4)
}
#subset for each model that belog to specific hars
Tmin_har2_district <- Tmin_2019[names(best_model_TMIN[-c(3, 9)])]
lapply(Tmin_har2_district, combined_mod_har2, poly_order = 1) -> final_model_Tmin_har2
#####################################################################
Tmin_har3_B_district <- Tmin_2019[names(best_model_TMIN[c(3)])]
lapply(Tmin_har3_B_district, combined_mod_har3_B, poly_order = 1) -> final_model_Tmin_har3_B
#####################################################################
Tmin_har3_C_district <- Tmin_2019[names(best_model_TMIN[c(9)])]
lapply(Tmin_har3_C_district, combined_mod_har3_C, poly_order = 1) -> final_model_Tmin_har3_C
#####################################################################
#######################COMBINE ALL TMIN##############################################
do.call(c,
list(
final_model_Tmin_har2,
final_model_Tmin_har3_B,
final_model_Tmin_har3_C
)) -> Tmin_final_model
# time series count validation check
length(names(Tmin_final_model))
Tmean_har2_district <- Tmean_2019[names(best_model_TMean[-c(4)])]
lapply(Tmean_har2_district, combined_mod_har2, poly_order = 1) -> final_model_Tmean_har2
#####################################################################
Tmean_har3_A_district <- Tmean_2019[names(best_model_TMean[c(4)])]
lapply(Tmean_har3_A_district, combined_mod_har3_A, poly_order = 1) -> final_model_Tmean_har3_A
#####################################################################
#######################COMBINE ALL TMEAN##############################################
do.call(c, list(final_model_Tmean_har2, final_model_Tmean_har3_A)) -> Tmean_final_model
# time series count validation check
length(names(Tmean_final_model))
Tmax_har3_A_district_ln <- Tmax_2019[names(best_model_TMax_ln[1:5])]
lapply(Tmax_har3_A_district_ln, combined_mod_har3_A, poly_order = 1) %>% set_names(names(Tmax_har3_A_district_ln)) -> final_model_Tmax_har3_A
#####################################################################
Tmax_har2_district_ln <- Tmax_2019[names(best_model_TMax_ln[c(6, 8)])]
lapply(Tmax_har2_district_ln, combined_mod_har2, poly_order = 1) %>% set_names(names(Tmax_har2_district_ln)) -> final_model_Tmax_ln_har2
#####################################################################
Tmax_har4_district_ln <- Tmax_2019[names(best_model_TMax_ln[c(7)])]
lapply(Tmax_har4_district_ln, combined_mod_har4, poly_order = 1) %>% set_names(names(Tmax_har4_district_ln)) -> final_model_Tmax_ln_har4
#####################################################################
Tmax_har2_district_cb <- Tmax_2019[names(best_model_TMax_cubic)]
lapply(Tmax_har2_district_cb, combined_mod_har2, poly_order = 3) %>% set_names(names(Tmax_har2_district_cb)) -> final_model_Tmax_cb_har2
#####################################################################
#######################COMBINE ALL TMAX##############################################
do.call(
c,
list(
final_model_Tmax_har3_A,
final_model_Tmax_ln_har2,
final_model_Tmax_ln_har4,
final_model_Tmax_cb_har2
)
) -> Tmax_final_model
# time series count validation check
length(names(Tmax_final_model))
#---FINAL MODEL
list(Tmin_final_model=Tmin_final_model, Tmean_final_model=Tmean_final_model,Tmax_final_model=Tmax_final_model) -> final
4.6 Creating test set using a combined quadratic and sin-cosine (of order 2) models.
A function return_quad_sin_cos was created to Estimate trend and seasonality using a combined quadratic and sin-cosine (of order 2) models. We created a function to apply the return_quad_sin_cos on a nested list called def_temp. The final outputs were joined into a list and called test.
# Function to return the harmonic mean of a time series data
return_quad_sin_cos <- function(takes_data) {
# Apply the run_model function to the data to get the specified model
run_model(takes_data, time.all) -> model.result
# Get the residuals from the data which does not have the trend
data.notrend <- takes_data - fitted(model.result$q_model)
# Create a matrix of SINE and COSINE values
SIN <- COS <- matrix(nrow = length(time.all), ncol = 6)
for (i in 1:6) {
SIN[, i] <- sin(2 * pi * i * time.all)
COS[, i] <- cos(2 * pi * i * time.all)
}
# Function to return harmonic of specified order
seasonal.har <- function(order) {
assign(paste(c("seasonal.har", order), collapse = ""),
lm(data.notrend ~ . - 1,
data.frame(SIN = SIN[, 1:order], COS = COS[, 1:order])))
return(get(paste(c(
"seasonal.har", order
), collapse = "")))
}
# order 2
seas.har2 <- seasonal.har(2)
return(seas.har2)
}
#function that applies lapply
def_temp <- function(takes_list) {
lapply(takes_list, return_quad_sin_cos) %>% set_names(names(takes_list)) -> res
return(res)
}
list_param <-
list(
"Tmin_2019" = Tmin_2019,
"Tmean_2019" = Tmean_2019,
"Tmax_2019" = Tmax_2019
)
lapply(list_param, def_temp) -> test
5 ARMA and Forecasting
5.1 Retrieving the residuals for test and final models
We subsetted the final and test model into subsets of the component parameters (Tmax,Tmean and Tmin), a function was created to derive the residuals for both final and test models. The mapply function was used to dervive the residuals by subtracting the combined model(final and test) from the original time series data. We removed trend and seasonality from each of the 30 time series for both the final and test model and hence we now have 60 residuals time series.
final$Tmin_final_model -> Tmin_final_model
final$Tmean_final_model -> Tmean_final_model
final$Tmax_final_model -> Tmax_final_model
test$Tmin_2019 -> Tmin_test_model
test$Tmean_2019 -> Tmean_test_model
test$Tmax_2019 -> Tmax_test_model
residuals_func <- function(ts_data,final_model){
residuals <- ts_data - final_model %>% fitted()
return(residuals)
}
#to apply mapply create a variable sorted names
sorted_district <- sort(names(Tmin_2019))
#we had to sort cause mapply works only on sorted
mapply(residuals_func, Tmin_2019[sorted_district], Tmin_final_model[sorted_district], SIMPLIFY = FALSE) -> residual_tmin
mapply(residuals_func, Tmean_2019[sorted_district], Tmean_final_model[sorted_district], SIMPLIFY = FALSE) -> residual_tmean
mapply(residuals_func, Tmax_2019[sorted_district], Tmax_final_model[sorted_district], SIMPLIFY = FALSE) -> residual_tmax
#we had to sort cause mapply works only on sorted
mapply(residuals_func, Tmin_2019[sorted_district], Tmin_test_model[sorted_district], SIMPLIFY = FALSE) -> test_residual_tmin
mapply(residuals_func, Tmean_2019[sorted_district], Tmean_test_model[sorted_district], SIMPLIFY = FALSE) -> test_residual_tmean
mapply(residuals_func, Tmax_2019[sorted_district], Tmax_test_model[sorted_district], SIMPLIFY = FALSE) -> test_residual_tmax
5.2 Fit the residuals with an appropriate ARMA model.
To fit a arma model to all our time series we created a function “fit_fun” which takes a residual as an argument and returns a model for our residuals. This was used to create forecasts for our time series later in this study. The lapply function was used to apply the fit_func function across our nested time series in both final and test set. We assigned the outcome into 6 different lists which reperesents Tmax, Tmean and Tmin for final and test model.
fit_func <- function(residuals) {
## Order selection -- AIC
n <- length(residuals)
norder <- 4
p <- c(1:norder) - 1
q <- c(1:norder) - 1
aic <- matrix(0, norder, norder)
for (i in 1:norder) {
for (j in 1:norder) {
modij <- arima(residuals,
order = c(p[i], 0, q[j]),
method = 'ML')
aic[i, j] <-
modij$aic - 2 * (p[i] + q[j] + 1) + 2 * (p[i] + q[j] + 1) * n / (n - p[i] -
q[j] - 2)
}
}
#aicv <- as.vector(aic)
#plot(aicv, ylab="AIC values")
indexaic <- which(aic == min(aic), arr.ind = TRUE)
porder <- indexaic[1, 1] - 1
qorder <- indexaic[1, 2] - 1
# Final residuals model
residuals.model <-
arima(residuals,
order = c(porder, 0, qorder),
method = "ML")
return(residuals.model)
}
lapply(residual_tmin, fit_func) %>% set_names(names(residual_tmin)) -> Tmin_residual_models
lapply(residual_tmean, fit_func) %>% set_names(names(residual_tmean)) -> Tmean_residual_models
lapply(residual_tmax, fit_func) %>% set_names(names(residual_tmean)) -> Tmax_residual_models
lapply(test_residual_tmin, fit_func) %>% set_names(names(test_residual_tmin)) -> Tmin_test_residuals
lapply(test_residual_tmean, fit_func) %>% set_names(names(test_residual_tmean)) -> Tmean_test_residuals
lapply(test_residual_tmax, fit_func) %>% set_names(names(test_residual_tmax)) -> Tmax_test_residuals
5.3 Forecasting
We will Forecast the average max, min and mean temperature for each month of 2020. We have to forecast the trend, seasonal components and rthe residuals which would then be combined to give our actual forecasts. Earlier in this analysis we observed that our best model for harmonics were splitted into 5 different configurations, we will implement similar solution here creating 5 different functions based on the 5 configurations. The functions were applied to their respective group of time series data and this gave us the final predictions for our models.
predict_har2 <- function(residuals.model, final_model, poly_order) {
ahead <- 12
pred.res <- predict(residuals.model, n.ahead = ahead)$pred
TIME.NEW <- seq(from = 2020,
by = 1 / 12,
length = ahead)
SIN.NEW <- COS.NEW <- matrix(nrow = length(TIME.NEW), ncol = 6)
for (i in 1:6) {
SIN.NEW[, i] <- sin(2 * pi * i * TIME.NEW)
COS.NEW[, i] <- cos(2 * pi * i * TIME.NEW)
}
pred_combined <-
predict(final_model,
newdata = data.frame(
TIME = poly(TIME.NEW, degree = poly_order, raw = TRUE),
SIN = SIN.NEW[, c(1, 2)],
COS = COS.NEW[, c(1, 2)]
))
love <- pred.res +pred_combined
return(love)
}
predict_har3_A <-
function(residuals.model, final_model, poly_order) {
ahead <- 12
pred.res <- predict(residuals.model, n.ahead = ahead)$pred
TIME.NEW <- seq(from = 2020,
by = 1 / 12,
length = ahead)
SIN.NEW <- COS.NEW <- matrix(nrow = length(TIME.NEW), ncol = 6)
for (i in 1:6) {
SIN.NEW[, i] <- sin(2 * pi * i * TIME.NEW)
COS.NEW[, i] <- cos(2 * pi * i * TIME.NEW)
}
pred_combined <-
predict(final_model,
newdata = data.frame(
TIME = poly(TIME.NEW, degree = poly_order, raw = TRUE),
#This is timeseries and param specific
SIN = SIN.NEW[, c(1, 2)],
COS = COS.NEW[, c(1, 2, 3)]
))
love <- pred.res +pred_combined
return(love)
}
predict_har3_B <- function(residuals.model, final_model, poly_order) {
ahead <- 12
pred.res <- predict(residuals.model, n.ahead = ahead)$pred
TIME.NEW <- seq(from = 2020,
by = 1 / 12,
length = ahead)
SIN.NEW <- COS.NEW <- matrix(nrow = length(TIME.NEW), ncol = 6)
for (i in 1:6) {
SIN.NEW[, i] <- sin(2 * pi * i * TIME.NEW)
COS.NEW[, i] <- cos(2 * pi * i * TIME.NEW)
}
pred_combined <-
predict(final_model,
newdata = data.frame(
TIME = poly(TIME.NEW, degree = poly_order, raw = TRUE),
#This is timeseries and param specific
SIN = SIN.NEW[, c(1, 2)],
COS = COS.NEW[, c(1, 2, 4)]
))
love <- pred_combined +pred.res
return(love)
}
predict_har3_C <- function(residuals.model, final_model, poly_order) {
ahead <- 12
pred.res <- predict(residuals.model, n.ahead = ahead)$pred
TIME.NEW <- seq(from = 2020,
by = 1 / 12,
length = ahead)
SIN.NEW <- COS.NEW <- matrix(nrow = length(TIME.NEW), ncol = 6)
for (i in 1:6) {
SIN.NEW[, i] <- sin(2 * pi * i * TIME.NEW)
COS.NEW[, i] <- cos(2 * pi * i * TIME.NEW)
}
pred_combined <-
predict(final_model,
newdata = data.frame(
TIME = poly(TIME.NEW, degree = poly_order, raw = TRUE),
#This is timeseries and param specific
SIN = SIN.NEW[, c(1, 2, 5)],
COS = COS.NEW[, c(1, 2)]
))
love <- pred_combined +pred.res
return(love)
}
predict_har4 <- function(residuals.model, final_model, poly_order) {
ahead <- 12
pred.res <- predict(residuals.model, n.ahead = ahead)$pred
TIME.NEW <- seq(from = 2020,
by = 1 / 12,
length = ahead)
SIN.NEW <- COS.NEW <- matrix(nrow = length(TIME.NEW), ncol = 6)
for (i in 1:6) {
SIN.NEW[, i] <- sin(2 * pi * i * TIME.NEW)
COS.NEW[, i] <- cos(2 * pi * i * TIME.NEW)
}
pred_combined <-
predict(final_model,
newdata = data.frame(
TIME = poly(TIME.NEW, degree = poly_order, raw = TRUE),
#This is timeseries and param specific
SIN = SIN.NEW[, c(1, 2, 4)],
COS = COS.NEW[, c(1, 2, 3)]
))
love <- pred_combined +pred.res
return(love)
#plot(time.all,Tmin_2019$Northern_Ireland,type = 'l',xlim = c(2000, 2021))
#lines(TIME.NEW,pred + pred.res,col = 'red',lwd = 2)
}
predict_test <- function(residuals.model, final_model) {
ahead <- 12
pred.res <- predict(residuals.model, n.ahead = ahead)$pred
TIME.NEW <- seq(from = 2020,
by = 1 / 12,
length = ahead)
SIN.NEW <- COS.NEW <- matrix(nrow = length(TIME.NEW), ncol = 6)
for (i in 1:6) {
SIN.NEW[, i] <- sin(2 * pi * i * TIME.NEW)
COS.NEW[, i] <- cos(2 * pi * i * TIME.NEW)
}
pred_combined <-
predict(final_model,
newdata = data.frame(
TIME = poly(TIME.NEW, degree = 2, raw = TRUE),
#This is timeseries and param specific
SIN = SIN.NEW[, c(1, 2)],
COS = COS.NEW[, c(1, 2)]
))
love <- pred_combined +pred.res
return(love)
#plot(time.all,Tmin_2019$Northern_Ireland,type = 'l',xlim = c(2000, 2021))
#lines(TIME.NEW,pred + pred.res,col = 'red',lwd = 2)
}
-TMIN MODELS
Tmin_har2_residuals <-
Tmin_residual_models[names(best_model_TMIN[-c(3, 9)])]
Tmin_har2_model <- Tmin_final_model[names(best_model_TMIN[-c(3, 9)])]
mapply(predict_har2,
Tmin_har2_residuals,
Tmin_har2_model,
1,
SIMPLIFY = FALSE) -> final_predict_Tmin_har2
#####################################################################
Tmin_har3_B_residuals <-
Tmin_residual_models[names(best_model_TMIN[c(3)])]
Tmin_har3_B_model <- Tmin_final_model[names(best_model_TMIN[c(3)])]
mapply(predict_har3_B,
Tmin_har3_B_residuals,
Tmin_har3_B_model,
1,
SIMPLIFY = FALSE) -> final_predict_Tmin_har3_B
#####################################################################
Tmin_har3_C_residuals <-
Tmin_residual_models[names(best_model_TMIN[c(9)])]
Tmin_har3_C_model <- Tmin_final_model[names(best_model_TMIN[c(9)])]
mapply(predict_har3_C,
Tmin_har3_C_residuals,
Tmin_har3_C_model,
1,
SIMPLIFY = FALSE) -> final_predict_Tmin_har3_C
#######################COMBINE ALL TMIN##############################################
do.call(
c,
list(
final_predict_Tmin_har2,
final_predict_Tmin_har3_B,
final_predict_Tmin_har3_C
)
) -> Tmin_final_predictions
# prediction validation check
length(names(Tmin_final_predictions))
-TMEAN MODELS
Tmean_har2_residuals <-
Tmean_residual_models[names(best_model_TMean[-c(4)])]
Tmean_har2_model <-
Tmean_final_model[names(best_model_TMean[-c(4)])]
mapply(predict_har2,
Tmean_har2_residuals,
Tmean_har2_model,
1,
SIMPLIFY = FALSE) -> final_predict_Tmean_har2
#####################################################################
Tmean_har3_A_residuals <-
Tmean_residual_models[names(best_model_TMIN[c(4)])]
Tmean_har3_A_model <-
Tmean_final_model[names(best_model_TMIN[c(4)])]
mapply(predict_har3_A,
Tmean_har3_A_residuals,
Tmean_har3_A_model,
1,
SIMPLIFY = FALSE) -> final_predict_Tmean_har3_A
#######################COMBINE ALL TMEAN##############################################
do.call(c,
list(final_predict_Tmean_har2, final_predict_Tmean_har3_A)) -> Tmean_final_predictions
# prediction validation check
length(names(Tmean_final_predictions))
-TMAX MODELS
Tmax_har3_A_residuals_ln <-
Tmax_residual_models[names(best_model_TMax_ln[1:5])]
Tmax_har3_A_model_ln <-
Tmax_final_model[names(best_model_TMax_ln[1:5])]
mapply(predict_har3_A,
Tmax_har3_A_residuals_ln,
Tmax_har3_A_model_ln,
1,
SIMPLIFY = FALSE) -> final_predict_Tmax_ln_har3_A
#####################################################################
Tmax_har2_residuals_ln <-
Tmax_residual_models[names(best_model_TMax_ln[c(6, 8)])]
Tmax_har2_model_ln <-
Tmax_final_model[names(best_model_TMax_ln[c(6, 8)])]
mapply(predict_har2,
Tmax_har2_residuals_ln,
Tmax_har2_model_ln,
1,
SIMPLIFY = FALSE) -> final_predict_Tmax_ln_har2
#####################################################################
Tmax_har4_residuals_ln <-
Tmax_residual_models[names(best_model_TMax_ln[c(7)])]
Tmax_har4_model_ln <-
Tmax_final_model[names(best_model_TMax_ln[c(7)])]
mapply(predict_har4,
Tmax_har4_residuals_ln,
Tmax_har4_model_ln,
1,
SIMPLIFY = FALSE) -> final_predict_Tmax_ln_har4
#####################################################################
Tmax_har2_residuals_cb <-
Tmax_residual_models[names(best_model_TMax_cubic)]
Tmax_har2_model_cb <- Tmax_final_model[names(best_model_TMax_cubic)]
mapply(predict_har2,
Tmax_har2_residuals_cb,
Tmax_har2_model_cb,
3,
SIMPLIFY = FALSE) -> final_predict_Tmax_cb_har2
#######################COMBINE ALL TMAX##############################################
do.call(
c,
list(
final_predict_Tmax_ln_har3_A,
final_predict_Tmax_ln_har2,
final_predict_Tmax_ln_har4,
final_predict_Tmax_cb_har2
)
) -> Tmax_final_predictions
# prediction validation check
length(names(Tmax_final_predictions))
mapply(predict_test,
Tmin_test_residuals,
Tmin_test_model[sorted_district],
SIMPLIFY = FALSE) -> Tmin_test_pred
mapply(predict_test,
Tmean_test_residuals,
Tmean_test_model[sorted_district],
SIMPLIFY = FALSE) -> Tmean_test_pred
mapply(predict_test,
Tmax_test_residuals,
Tmax_test_model[sorted_district],
SIMPLIFY = FALSE) -> Tmax_test_pred
5.4 Model Comparison
We will be evaluating the accuracy of our predictions using the accuracy function of the forecast library, we used the subsetted time series of 2020 data for all our time series as the actual while outcome of our predictions for 2020 as the predicted. We are going to observe our models performance with unseen data not used when fitting the model. The mapply function was used to apply the model_accuracy function across all our different time series predictions for best test and final.
model_accuracy <- function(y.pred, y.ts) {
y.actual <- window(y.ts, start = 2020)
accuracy(y.pred, y.actual)
}
mapply(model_accuracy, Tmin_final_predictions[sorted_district], Tmin[sorted_district], SIMPLIFY = FALSE) -> Tmin_accuracy
mapply(model_accuracy, Tmean_final_predictions[sorted_district], Tmean[sorted_district], SIMPLIFY = FALSE) -> Tmean_accuracy
mapply(model_accuracy, Tmax_final_predictions[sorted_district], Tmax[sorted_district], SIMPLIFY = FALSE) -> Tmax_accuracy
mapply(model_accuracy, Tmin_test_pred[sorted_district], Tmin[sorted_district], SIMPLIFY = FALSE) -> Tmin_accuracy_test
mapply(model_accuracy, Tmean_test_pred[sorted_district], Tmean[sorted_district], SIMPLIFY = FALSE) -> Tmean_accuracy_test
mapply(model_accuracy, Tmax_test_pred[sorted_district], Tmax[sorted_district], SIMPLIFY = FALSE) -> Tmax_accuracy_test
get_rmse<-function(x,y){
y[[x]][2]-> a
return(a)
}
#function to get rmse of all time series
get_all_rmse <- function(Tmin,Tmean,Tmax){
lapply(names(Tmin), get_rmse,y=Tmin) %>% set_names(names(Tmin)) %>% as.data.frame() %>% t() %>% as.data.frame() %>% set_names("Tmin_rmse") -> Tmin_rmse
lapply(names(Tmean), get_rmse,y=Tmean) %>% set_names(names(Tmean)) %>% as.data.frame() %>% t() %>% as.data.frame() %>% set_names("Tmean_rmse") -> Tmean_rmse
lapply(names(Tmax), get_rmse,y=Tmax) %>% set_names(names(Tmax)) %>% as.data.frame() %>% t() %>% as.data.frame() %>% set_names("Tmax_rmse") -> Tmax_rmse
return(cbind(Tmin_rmse,Tmean_rmse,Tmax_rmse))
}
We observe the rmse for our models below, we can see the rmse for both the test model and final model, we observed that for some regions the test model performed better than the final model according to the rmse figures in the tables below.
get_all_rmse(Tmin_accuracy,Tmean_accuracy,Tmax_accuracy)
get_all_rmse(Tmin_accuracy_test,Tmean_accuracy_test,Tmax_accuracy_test)


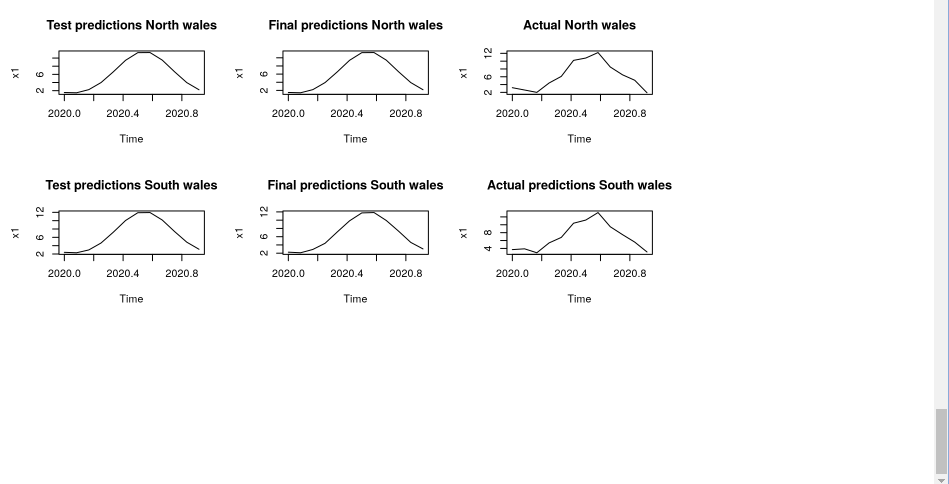
We focused our analysis on the values from the test model predictions, final model predictions and the actual predictions for the South wales and North wales region, a plot was implemented and we observe that the plots are similar for the three different variables for north and south wales.
Tmin_test_pred$England_NW_and_N_Wales %>% as.data.frame() %>% set_names("test_predictions")-> test_N_wales
Tmin_final_predictions$England_NW_and_N_Wales %>% as.data.frame() %>% set_names("final_predictions") -> final_N_wales
Tmin$England_NW_and_N_Wales %>% window(start = 2020) -> England_NW_and_N_Wales_actual
England_NW_and_N_Wales_actual %>% as.data.frame()%>% set_names("Actual") -> actual_N_wales
cbind.data.frame(test_N_wales,final_N_wales,actual_N_wales)

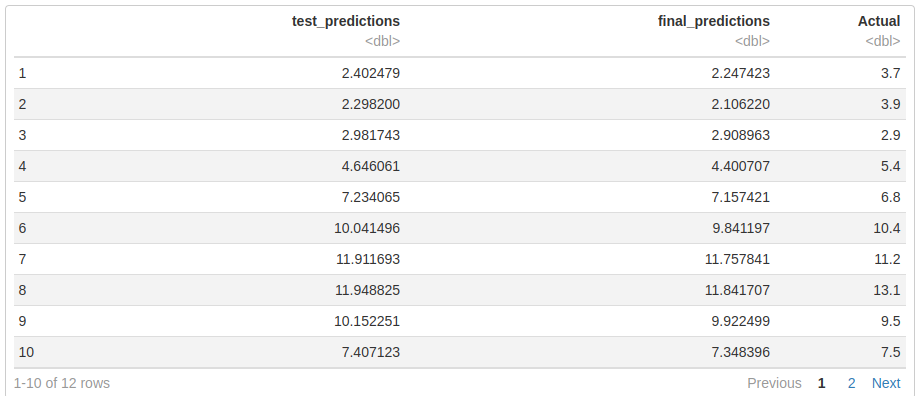
Tmin_test_pred$England_SW_and_S_Wales %>% as.data.frame() %>% set_names("test_predictions")-> test_S_wales
Tmin_final_predictions$England_SW_and_S_Wales %>% as.data.frame() %>% set_names("final_predictions") -> final_S_wales
Tmin$England_SW_and_S_Wales %>% window(start = 2020) -> England_SW_and_S_Wales_actual
England_SW_and_S_Wales_actual %>% as.data.frame()%>% set_names("Actual") -> actual_S_wales
cbind.data.frame(test_S_wales,final_S_wales,actual_S_wales)
par(mfrow=c(3,3))
plot(test_N_wales,main = "Test predictions North wales")
plot(final_N_wales,main = "Final predictions North wales")
plot(actual_N_wales,main = "Actual North wales")
plot(test_S_wales,main = "Test predictions South wales")
plot(final_S_wales,main = "Final predictions South wales")
plot(actual_S_wales,main = "Actual predictions South wales")